
Un outil de test de montée en charge est un outil permettant de simuler un grand nombre d’utilisateurs sur une application dans le but de savoir si celle-ci va tenir la charge, c’est à dire pour savoir si celle-ci sera capable de gérer toutes les requêtes des utilisateurs et fournir un service répondant aux critères de qualités fixés ( temps de réponse satisfaisant, contenu des réponses correct etc…). Il existe une multitude d’outils permettant cela mais il est intéressant de comparer ces différents outils car selon les machines disponibles pour exécuter ces tests, certains outils sont plus adaptés que d’autres.
Les solutions open-source
Cette image tirée d’un article du blog de Redline13 https://www.redline13.com/blog/ montre les différentes fonctionnalités des divers outils open-source de test de montée en charge. Nous ne nous intéresserons qu’aux solutions proposant toutes les fonctionnalités du comparatif, c’est à dire les solutions distribuées, avec un recorder (outil permettant d’enregistrer un scénario), proposant des graphiques, des plugins et pouvant être intégré avec Jenkins. On peut donc s’intéresser à :
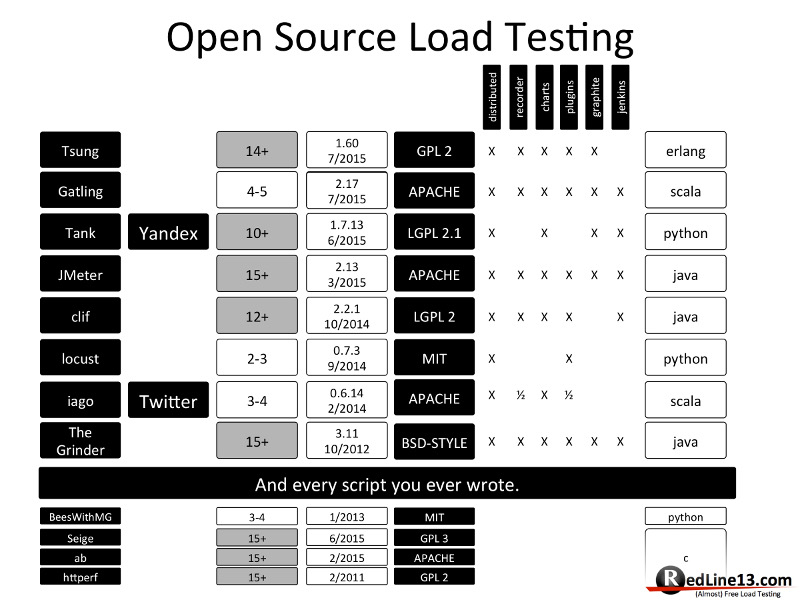
Cette image tirée d’un article du blog de Redline13 https://www.redline13.com/blog/ montre les différentes fonctionnalités des divers outils open-source de test de montée en charge. Nous ne nous intéresserons qu’aux solutions proposant toutes les fonctionnalités du comparatif, c’est à dire les solutions distribuées, avec un recorder (outil permettant d’enregistrer un scénario), proposant des graphiques, des plugins et pouvant être intégré avec Jenkins. On peut donc s’intéresser à :
- Gatling : développé en Scala et basé sur Akka et Netty.
- JMeter : développé à 100% en Java.
- Grinder : Également développé en Java.
Exécuter un test de charge n’est clairement pas la chose la plus compliquée à faire. Les experts en performances sont conscient que le plus difficile reste l’interprétation des résultats de ces tests dans le but de trouver la cause du potentiel problème de performance. C’est pourquoi l’un de nos critères sera tout simplement la qualité du rapport final de chaque test. En suite, un autre critère sera la capacité de la technologie à Scaler et à générer un grand nombre d’utilisateurs simultanément.
JMeter, Grinder et beaucoup d’autres outils de tests de charges utilisent un thread par utilisateur virtuel ce qui n’est pas le cas de Gatling qui lui utilise Akka qui est basé sur la programmation concurrente acteur. Concrètement cela permet en théorie à Gatling de générer une charge très importante, voir plus importante que les autres outils. Cependant, en parcourant divers articles et forums, beaucoup montre que les performances de gatling ne sont pas aussi supérieur, comme on pourrait le croire, que celles de JMeter ou d’autres outils on peut même noter Dmitri Tikhanski qui publie des résultats de tests dans cet article de Blazemeter :
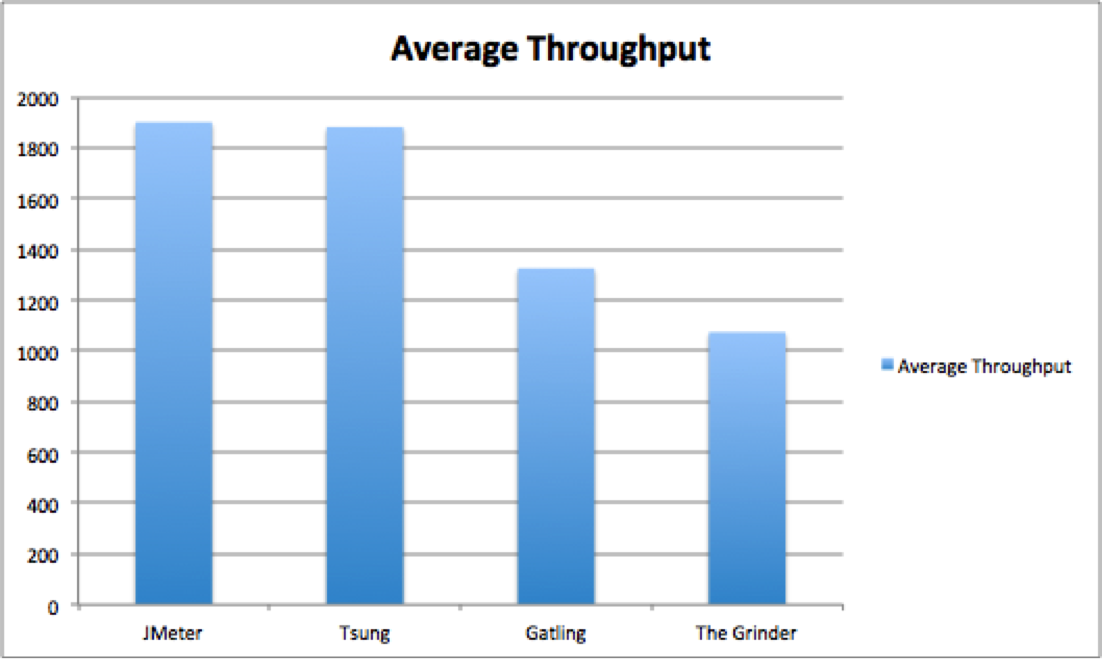
Ces résultats qui sont la comparaison du nombre de requêtes par minute pour chaque logiciel nous montre que JMeter est clairement au dessus de Gatling et Grinder (Et tsung dont nous ne parlerons pas dans cet article). Le scénario du test était simple, une requête HTTP avec 20 threads et 100000 itérations exécutée avec un client ayant un CPU 4 coeurs à 2.7Ghz, 4 GO de RAM et Ubuntu. Le résultat est donc sans appel et JMeter remporte la partie haut la main. Cependant, ici nous ne parlons que d’exécuter une requête et pas de simuler des utilisateurs avec un véritable scénario, donc on ne peut pas se baser uniquement sur cette étude. J’ai donc recherché d’autres études montrant les trois technos, mais j’ai été forcé à reconnaître que je n’en trouverai pas sans m’aventurer dans les méandres de la 50ème page de google. J’ai donc trouvé une paire d’article de Flood.io qui est un service permettant de déployer des tests avec Gatling et Jmeter (ce qui est important car on peut supposer une certaine impartialité des tests). Ces deux articles (sources 3 & 4) montrent les résultats de deux tests différents :
Le premier test est un scénario où il est généré 10k utilisateurs et 30k requêtes par minutes.
Le deuxième est un scénario simulant 20k puis 40k utilisateurs.
Ces deux tests sont exécutés sur une JVM ayant 4GB de RAM et on peut voir dans le premier test, mais de manière nettement moins marqué, que JMeter est toujours meilleur que Gatling au niveau du temps de réponse :
| Tool | Benchmark | Mean RT +/- SDev |
|---|---|---|
| Gatling-1.5.3 | 10,000 Users | 1788 +/- 362 ms |
| JMeter-2.9 | 10,000 Users | 1625 +/- 322 ms |
| JMeter-2.10 | 10,000 Users | 1698 +/- 31 ms |
Cependant, dans le deuxième cas, les valeurs sont tout autre :
| Tool | Benchmark | Mean RT +/- SDev |
|---|---|---|
| Gatling-1.5.3 | 20,000 Users | 1702 +/- 28 ms |
| JMeter-2.9 | 20,000 Users | 2637 +/- 1015 ms |
| JMeter-2.10 | 20,000 Users | 2143 +/- 446 ms |
Ce deuxième test nous montre donc que Gatling est capable de supporter le double d’utilisateur sans perdre en qualité de temps de réponse, ce qui n’est pas étonnant étant donné qu’il est basé sur Akka qui est fait pour supporter de grandes charges concurrentes. JMeter lui voit son temps de réponse se dégrader significativement. On peut donc imaginer que Gatling peut générer plus de charge. Le test ne s’arrête pas là, Flood.io a décidé de tester à 40k utilisateurs et les résultats montrent que Gatling, malgrès une dégradation de ses performances, est capable de tenir la charge alors que JMeter voit la mémoire de sa JVM saturer.
Avec ces sources, on peut voir que les deux solutions qui dominent le marché Open Source au niveau des performances sont Gatling et JMeter et selon Flood.io, Gatling serait capable de générer plus de charge.
Notre deuxième critères est basé sur la qualité des rapports produit à la fin du test de charges. Pour cela nous allons tout simplement regarder les rapports produits par ces trois solutions.
JMeter
JMeter, selon sa documentation, permet de générer des rapports personnalisés grâce à un simple fichier de configuration qui ressemble à ceci :
1 | jmeter.save.saveservice.bytes = true |
On peut trouver ce tableau sur la documentation de JMETER :
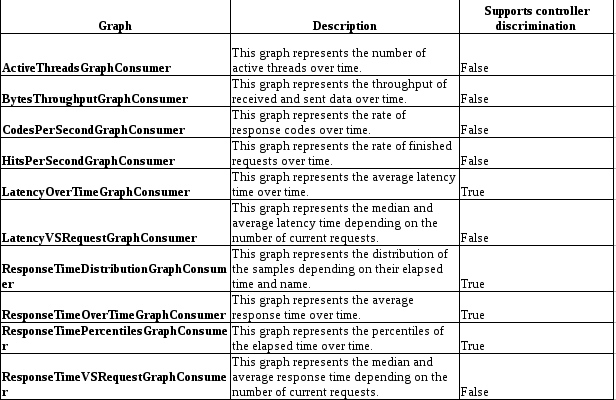
Cela montre qu’il y a un bon nombre de données disponibles “out of the box”, comme
- le code et les messages des réponses aux requêtes
- la latence
- Est-ce que la requête est un succès
- le temps d’exécution des requêtes
- le nom du thread
- le nombre de threads
- La date et l’heure d’exécution des requêtes
Il y a également d’autres paramètres pour générer des rapports un peu plus personnalisés avec un titre précis, des charts d’une certaine forme, des limites pour l’APDEX (Application Performance Index), la granularité des charts, changer le nom/dossier d’export du rapport…
En ce qui concerne les charts, je ne vais pas toutes les montrer car cela serait inutile mais vous pouvez aller consulter la documentation (source 5). Voici un exemple de chart générée
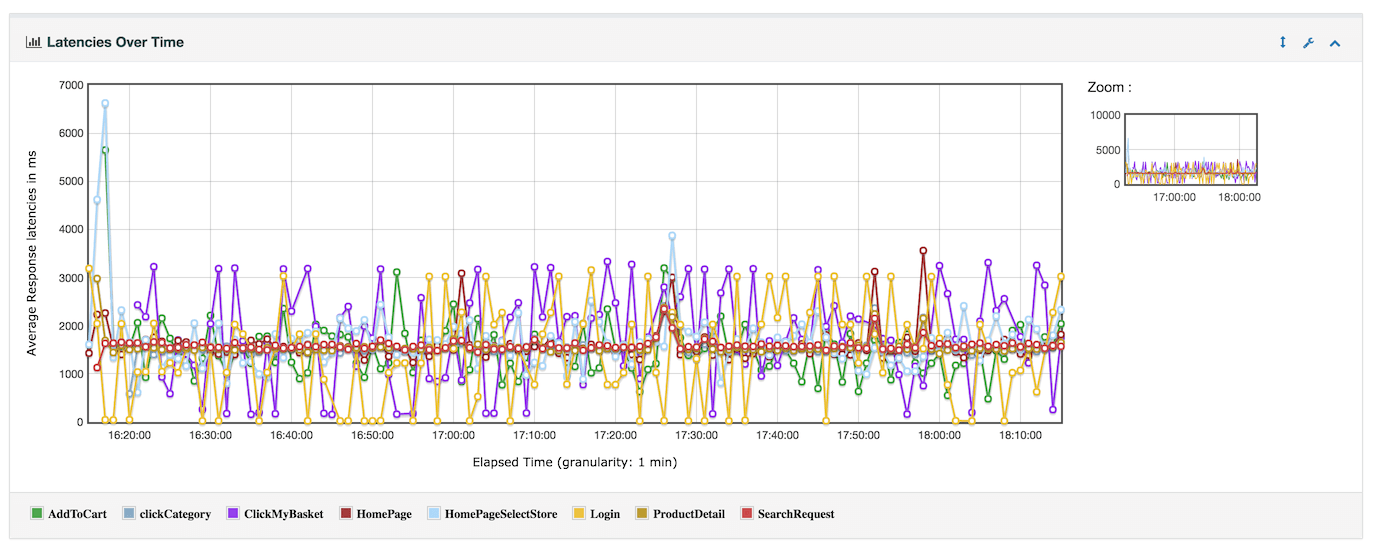
On peut voir que ces charts sont plutôt modernes, lisibles, et il est possible de zoomer, afficher cacher des informations pour permettre une meilleure visibilité et donc une plus grande facilité dans l’interprétation et la mise en valeur des données importantes.
Grinder
Grinder est, comme JMeter, Développé en Java. Celui-ci ne propose pas de solutions pour créer des graphs “out of the box”. Cependant celui propose quand même de relever certaines données. Selon la documentation :
- Les requêtes ayant réussi.
- Des statistiques sur les temps de réponses
- Relever des statistiques personnalisés
Ces statistiques sont visible dans la console de Grinder et dans le terminal (selon comment on lance le script) mais par contre il n’y a pas de graphiques fournis. Par contre il existe quand même des solutions comme g2g permettant de générer des graphiques facilement.
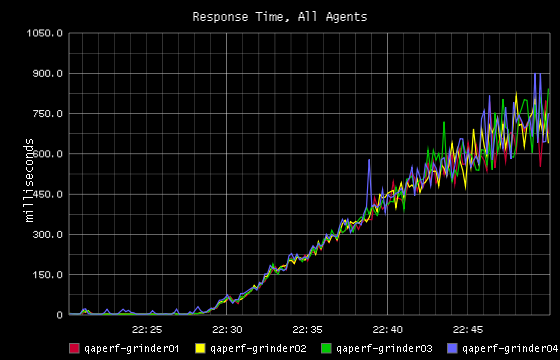
Gatling
Gatling propose beaucoup de métriques :
- Nombres de requêtes, triées en fonction du temps de réponses (définissable avec les threshold).
- Des statistiques sur les temps de réponses (min, max, moyenne, médiane).
- Les codes erreurs trouvés et leur occurence.
- Nombre de requêtes et nombre de réponses par secondes.
- D’autres agrégations des du nombre de requêtes.
Ces données sont agencées de deux manières, soit dans un graphe comme les différents temps d’exécution des requêtes :
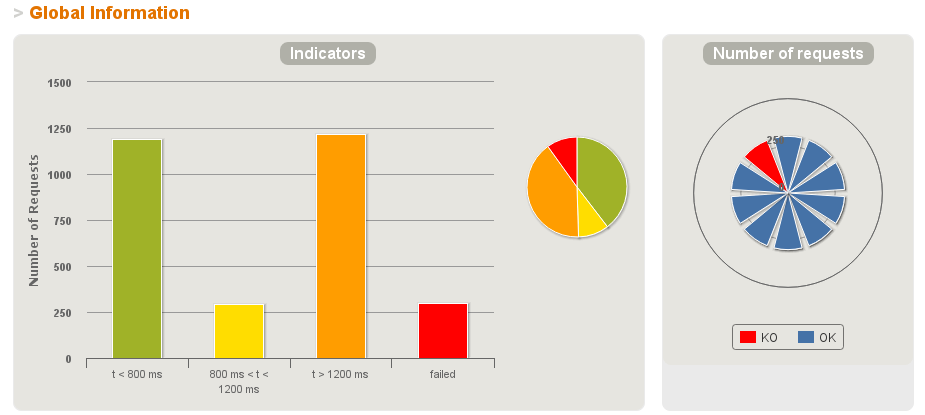
Soit dans un tableau comme les statistiques :
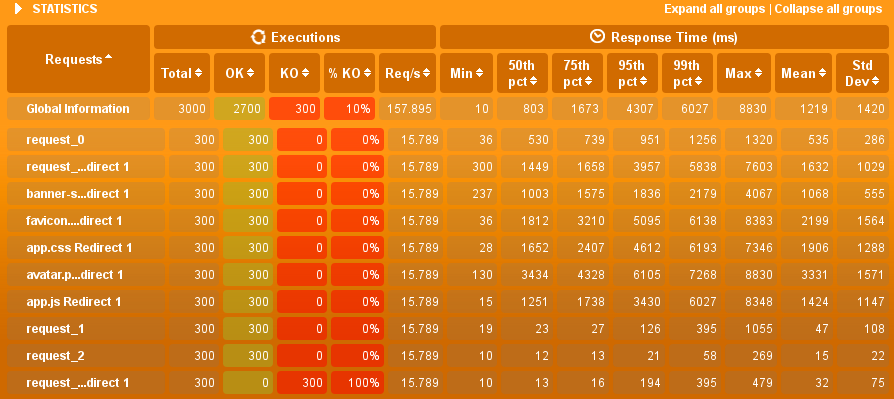
Dans tous les cas, Gatling présente autant de données que JMeter et Grinder mais a un rendu des rapports différents, ces rapports sont plus facile à interpréter que la console de Grinder. Enfin, les Graphes de Gatling sont à mon sens équivalent à ceux de JMeter.
Donc finalement quel outil open source ?
Et bien comme d’habitude, ça dépend ! Gatling est plus capable pour scaler sur une seule machine du fait de son architecture basée sur Akka, mais celui-ci utilise le langage Scala pour ses scripts qui, même si il se popularise beaucoup, reste peu inconnu pour de nombreux développeurs. Grinder et JMeter eux utilisent respectivement le Jython et le Java ce qui les rends les scénarios plus facile à scripter pour la plupart des développeurs. Je pense que JMeter et Gatling sont au dessus du lot dans le sens où ils fournissent des rapports de bien meilleur qualité “out of the box” et qu’ils ont, selon les tests que j’ai pu voir, de meilleurs capacités à générer de la charge. Cependant, n’oublions pas que ces trois outils proposent des plugins, donc il pourrait être intéressant d’investiguer de manière plus approfondie dans les plugins proposés par Grinder pour voir si celui-ci ne pourrait pas, avec une bonne configuration, être aussi voir plus puissant que Gatling et JMeter.
Sources
- https://www.redline13.com/blog/2015/09/9-open-source-load-testing-review/
- https://www.blazemeter.com/blog/open-source-load-testing-tools-which-one-should-you-use
- https://blog.flood.io/benchmarking-jmeter-and-gatling/
- https://blog.flood.io/stress-testing-jmeter-and-gatling/
- http://jmeter.apache.org/usermanual/generating-dashboard.html
- http://www.coderewind.com/2014/07/top-6-performance-testing-tools/